Battle of the Neighborhoods
IBM Applied Data Science Professional Certificate — Capstone Project
As part of the 9 Course series from the IBM Applied Data Science Specialization offered by IBM on Coursera, the 9th course tests us on our ability to make an independent project.
This project demands the use of Foursquare API for Data Analysis and allows us to implement the various techniques learnt during the specialization. This includes various Data Visualisation Techniques.

Introduction
This report is part of the Capstone Project for IBM’s Applied Data Science Professional Certificate offered by Coursera. This is part of the final course in this 9-course series.
We will be using several data visualization techniques, in particular, we will be making use of Foursquare API to retrieve location data for the state of Toronto in Canada and use this data to perform data analysis.
Introducing the Project
- Background
Toronto is a big state with numerous neighbourhoods. Each neighbourhood has its share of shops, restaurants, cafes, beaches etc. The different places add to the vibrance of the state and make it a great place to live and travel for others. The place also provides many opportunities for entrepreneurs, especially those that want to start afresh. Being so close to the capital of Canada, it receives its fair share of foot traffic from foreigners. In this project, we aim to analyze the various places in Toronto using location data imported from the Foursquare API.
2. The Problem
If a person has to open a new restaurant in a neighbourhood in Toronto then what neighbourhood should he/she choose based on the restaurant type. And if they have a specific restaurant type in mind then what place would be best ensuring a good amount of customer traffic but also keeping in mind the amount of competition. We also cluster the neighbourhoods based on the most popular spots to visit so that we can make it easier for a new business person to choose the right neighbourhood for their restaurant/shop.
3. Interest
This report will be useful for those who want to start a new business in the state of Toronto. It will also be helpful for those who want to travel to Toronto and want to visit specific locations based on their interest. For example, if a tourist wants to visit multicultural restaurants in Toronto, then what neighbourhoods are best? They should ideally visit those neighbourhoods where multicultural restaurants are popular among the people. The clustering of the neighbourhoods based on the most visited spots allows people to decide where to travel and explore more. Clusters tell us what neighbourhoods are fairly similar to each other so the person can skip travelling to many of the same neighbourhoods.
Data Acquisition and Cleaning
- Data Available
We make use of a few data sources to get the data required for this project. We get different kinds of Neighborhoods in Toronto along with the Boroughs and Postal codes from Wikipedia:
We get the Latitudes and Longitudes for each postal code through the CSV file provided to us by the Coursera Applied Data Science Capstone Week 3 Module. We get the various location-related data, like the kinds of places in a particular neighbourhood, using Foursquare API. This data will include the type of shops, restaurants, cafes, beaches etc in each neighbourhood.
2. Acquiring the Data
We acquire the data about the various neighbourhoods, boroughs and postal codes from the Wikipedia page using Beautiful Soup. We put it into a data frame. The latitudes and longitudes are in a CSV file that can be read using pandas. We will make calls to Foursquare API using our credentials to acquire the location-related data.
3. Cleaning the data
Once we have our data that includes the Postal Codes, Boroughs and Neighbourhoods in Canada, we drop all rows where the borough is unknown. We want to focus on the data that has been assigned a borough.
More than one neighbourhood can exist that has the same postal code, we combine such rows. We make a single row for each postal code and the subsequent neighbourhoods that are associated with that postal code would be put into the same row separated by commas.
If a particular postal code does not have a neighbourhood assigned but that row has an assigned borough, then the neighbourhood is considered to be the same as the borough.
We sort the data by the postal codes.
Then we merge the data frame with the stored values of the latitudes and longitudes of each postal code.

Here we get our final data frame.
4. Feature Selection
We want to focus on neighbourhoods in Toronto. So we drop all rows that have Boroughs outside of Toronto. We keep the data from Toronto. Finally, our data frame is ready to use.
Exploratory Data Analysis
- Visualizing the data
We can visualize the various neighbourhoods in Canada by drawing a map and plotting the neighbourhoods on top. This allows us to see what we are dealing with and how the neighbourhoods are scattered.
We need to focus on the neighbourhoods in Toronto. We have already made a separate data frame with data from Toronto (i.e. East, West, North and Downtown Toronto). We visualize this data using a map centred in Toronto but only plotting the neighbourhoods in Toronto.
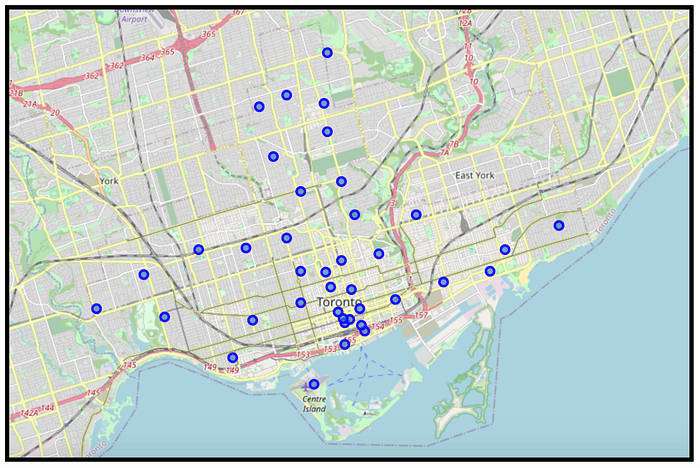
2. Exploring the Neighborhoods
We now see how we can find out what venues are there in each neighbourhood in Toronto. We can do this by exploring any one neighbourhood. The process would then be similar for all subsequent neighbourhoods.
We find what is the first neighbourhood in our list of neighbourhoods in Toronto. It is “The Beaches”. We use Foursquare API to get the top 100 venues that are in The Beaches within a radius of 700 metres. This gives us an idea of the types of locations that can be present in a neighbourhood.
The first 5 of these venues are :
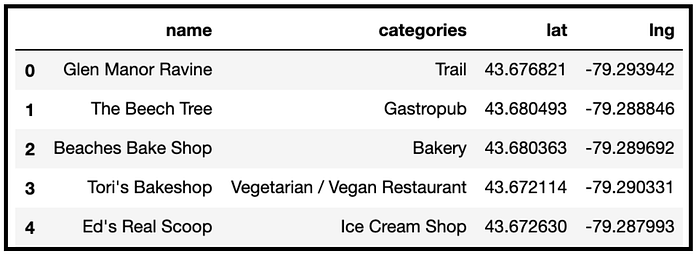
We can see that around “The Beaches”, few of the locations include a Trail, Gastropub, Bakery, Vegan Restaurant and Ice Cream shop. Each venue has its assigned category along with the latitudes and longitudes.
Similarly, we can explore the other neighbourhoods and this information can be very useful for a potential business owner wanting to start a new business in any of the neighbourhoods.
Methodology
- Exploring the various places with different categories
Our first step is making a dataset with all the neighbourhoods along with the different venues near that neighbourhood. This dataset will allow us to group the neighbourhoods together according to the similarity in the type of venues in each neighbourhood. For example, if two neighbourhoods are very popular for their beaches and cafes then they can be put into the same group.

Now we have a dataset of all the neighbourhoods and their corresponding venues along with the categories of the venues.
2. Grouping the neighbourhoods based on the topmost common venues
Using the above dataset, we can start to group the neighbourhoods based on the similarity of their topmost venues. If two neighbourhoods have the same top few venues then they can be groups together in the same row. We make use of the mean of the frequency of the occurrence of each category and combine the neighbourhoods with similar venues. We make a data frame of the postal codes along with the grouped neighbourhoods and the top 10 most common venues.
The top 5 rows of this data frame will look like :

This clearly shows the similar neighbourhoods in the same row along with the top 10 most popular places in those neighbourhoods.
3. Clustering the data
We will cluster the data using KMeans Clustering.
We already have our grouped data where similar neighbourhoods have been grouped together based on the top venues in these neighbourhoods. We can now perform KMeans Clustering to associate each group to a cluster. We cluster these neighbourhoods into 5 clusters and label them accordingly.
We will then analyze based on the clusters how similar the neighbourhoods are to each other. Neighbourhoods in the same cluster are likely to have similar categories of venues and thus opening a new branch for the business in the same cluster will not be ideal.


Results
Most of the neighbourhoods in Toronto fall in the same cluster (Indicated in Blue). The neighbourhoods in the Red cluster are mainly on the outskirts of Toronto.
There are 2 neighbourhoods that form their own cluster and one cluster (indicated in purple) consists of only 2 neighbourhoods.
Since the neighbourhoods were clustered based on the similarity in the categories of popular venues, it can be observed that most neighbourhoods have the same category of venues.
Discussion
Our aim was to help potential business owners and tourists in picking our the right neighbourhood to travel or open a business in. For example, if a business owner wants to open a Vegan Cafe, he/she must choose the neighbourhood carefully making sure that there aren’t any other popular Vegan Cafes in the same location. If so, he/she can face a lot of competition from an already established place.
But they should also keep in mind the interest of the people. People in a particular neighbourhood should be interested in the entrepreneur’s business.
Also, when tourists visiting Toronto plan their holiday, they would want to visit different kinds of places. Visiting neighbourhoods that have almost the same characteristics would not be ideal.
This is why our aim was to cluster the neighbourhoods based on their similarity, i.e, their most popular locations. For example, if two neighbourhoods are popular for Indian restaurants, then both of them can be put into the same cluster. This alerts business owners that if they want to open a particular kind of restaurant and one neighbourhood is not ideal, then all neighbourhoods in that cluster are not ideal. This also gives them an idea about how they can scale profitably and open more branches in different clusters.
Conclusions
The clusters allow interested people to understand how similar neighbourhoods are in Toronto.
Using the data about the 10 most popular venues in each neighbourhood group allows people to choose the right neighbourhood for starting a new business or opening a new branch for their already existing business.
The similarity in neighbourhoods allows tourists to decide which places they should add on the to-visit list without making redundant choices. It also tells them what are the most popular places n each neighbourhood that they must visit.
This project has been done with help from the labs provided by the IBM Applied Data Science Capstone Course on Coursera. Certain ideas for this project have been taken from the labs.
All pictures used are my own.
You can find my GitHub code for this project here :
