Simple Text Web Scraping with Deployment
A simple use-case of scraping text and creating a Heroku app.
Web scraping, also known as web harvesting, is when we extract data from websites. I dived into the world of web scraping through a simple use case of scraping Customer Reviews from India’s largest Online Store — Flipkart.com
If you're only here for the final product, then here is it is —
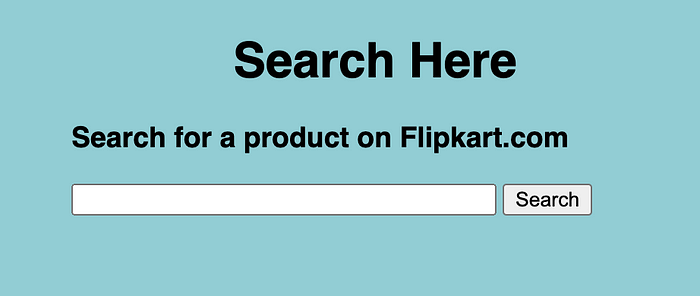
Just search keywords of what you want to see (example: iPhone SE), and click the search button to load reviews from Flipkart.com


Why is the app not working for me?
If you're trying to load the search results and it isn't showing you the desired output, the possible reasons must be —
- You’ve searched a really complicated query, something with a lot of numbers, special characters or too many spaces. Although, the program is written is tackle these issues, sometimes it just may not work. Try simpler text keywords!
- The class IDs of the data scraped has been changed! If this is the case, I just need to update the changed class IDs and it’ll work just fine. I’ll try to do this as soon as I can, but till then, I’m so sorry you couldn't try the app yourself :(
How I scraped the data
I used the following for this use case —
- Flask: To create the API
- Beautiful Soup: To actually scrap the data
I started off with asking the user to enter keywords of what they want to search, I took this data using an HTML form. Once I had the keywords, I deleted the spaces in between so that I can create the desired Flipkart URL to get to the search results.
searchString = request.form['content'].replace(" ","")
flipkart_url = "https://www.flipkart.com/search?q=" + searchString
Using urllib.request library, I can read the page. Then, I used Beautiful Soup to get the page from where I can extract data from HTML. Check out my Github profile (link given below) to get the detailed commands for how I did it.
We need to one-by-one, click on each of these product listings to get to the customer reviews.

I extracted the link to the product using the HTML code.
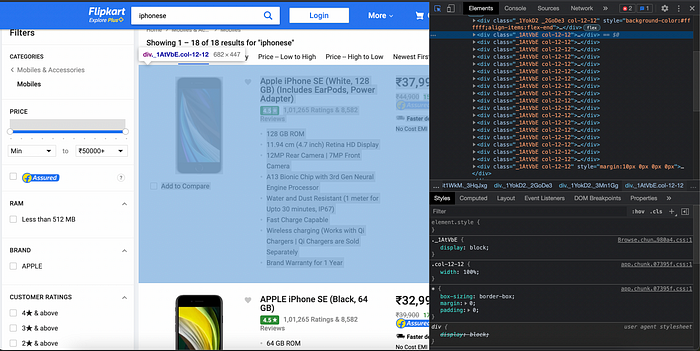
The product listings have a class ID of “_1AtVbE col-12–12”, so we use this to get to the link of each product.
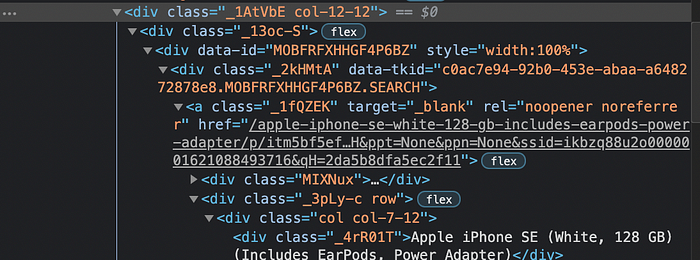
Once we’re at the product page, we need to specifically target the reviews from customers-

We again use Beautiful Soup to read this page and look for the desired class ID that we need. Each review block has the class ID “_16PBlm”.
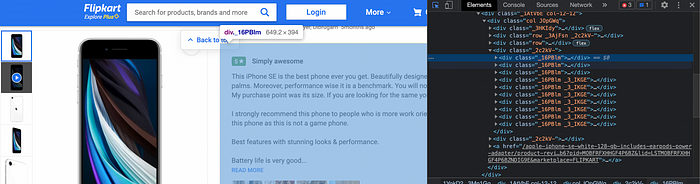
Expanding these further, we target the Name, Date, Rating, Comment Title, Comment Body of each review and store that data in a dictionary. This dictionary of all the data is what we pass to the HTML document that displays it in the table as final results.
How I created the web pages
The Search Page
The Search page makes use of HTML forms to get the data (the keywords) that we need to search.
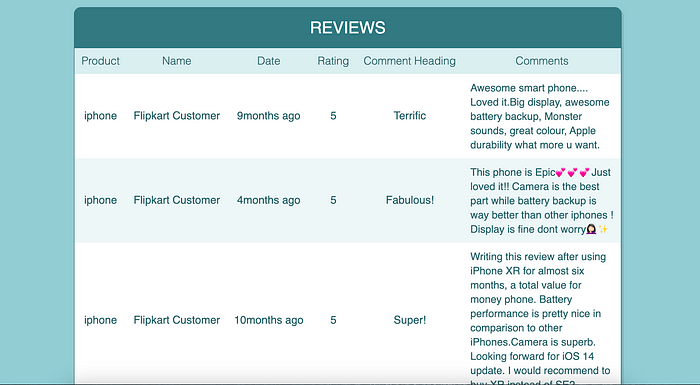
The Results Page
The Results page makes use of simple HTML table commands to display the data in a tabular form.
Both HTML pages are linked with CSS codes to make them look better. The Web pages are as basic as I could go so that I can easily check if the python code works or not.
Saving the Scraped Data
If run in my local system, on an IDE like PyCharm, the program creates a .csv file for each search result and keeps all the scraped data in that file. This was done using the basic file writing commands in Python.
If connected to MongoDB, the program can be easily adapted to store the scraped data into a database as well.
How I deployed the App
The app is deployed using Heroku. It starts off as a free platform so it was definitely a good choice for my first deployment. I just had to download Heroku into my system, log in using the Terminal, and then follow the steps on the Heroku dashboard to push the code into deployment.
What I could have done better
Since this was my first time scraping data off the web, I tried to keep it as simple as I possibly could. There are many ways in which I could have made the app a lot better and more close to a real-world use case. I’m exploring to add the following things into my next project that uses web scraping :
- Integrating it with MongoDB - I had connected the program with MongoDB on my local machine in my first run, however, at the time of deployment, I removed that chunk of code. I could connect the program with the MongoDB Atlas so that I can save my scraped results for future reference.
- Making the Web pages better — I’m not a web developer, and definitely don't have any experience creating web pages with HTML and CSS. I tried to stick with the simplest web page I possibly could, whose templates I could find. I plan to make the web pages slightly better in the future.
- Scrap more detailed data- I would be trying out scraping more detailed data, including product prices, EMI options, and Product sellers.
- Tackle the changing class IDs- Since class IDs of the scraped data can be changed/updated at any time, the program can stop working whenever this happens. A way around this is by using the Xpath of the objects that are to be scraped. This can be easily done if we use Selenium instead of beautiful soup to scrap data.
Look at the full code on my GitHub:
This code would not have been possible without the iNeuron team, whose lectures are what I followed to achieve this code.
